适用于版本3.1.2
1 安全
默认关闭。详见Spark Security
2 用户识别
项目构建的镜像中默认包含了UID为185的用户。
使用docker-image-tool.sh脚本构建时通过-u选项设置UID。
此外,Pod Template 允许向Spark提交的Pod中添加带有runAsUser的Security Context。
集群管理员应该使用Pod Security Policies限制可以使用的用户。
3 Volume挂载
注意hostPath存在安全隐患,管理员应该使用策略加以限制。
4 前提
版本>=2.3
k8s版本>=1.6, 并且开启了kubectl。
测试环境可以在本地使用minikube。
- 推荐使用最新版本,并且开启了DNS addon。
- 默认配置资源不足以运行Spark。单个执行阶段推荐使用3 CPU和4G内存。
具有增删改查Pod的权限。
可以使用以下命令验证:
1
kubectl auth can-i <list|create|edit|delete> pods
- 驱动pod使用的服务账号证书必须具有创建pod、service和configmap的权限。
必须配置Kubernetes DNS。
5 原理
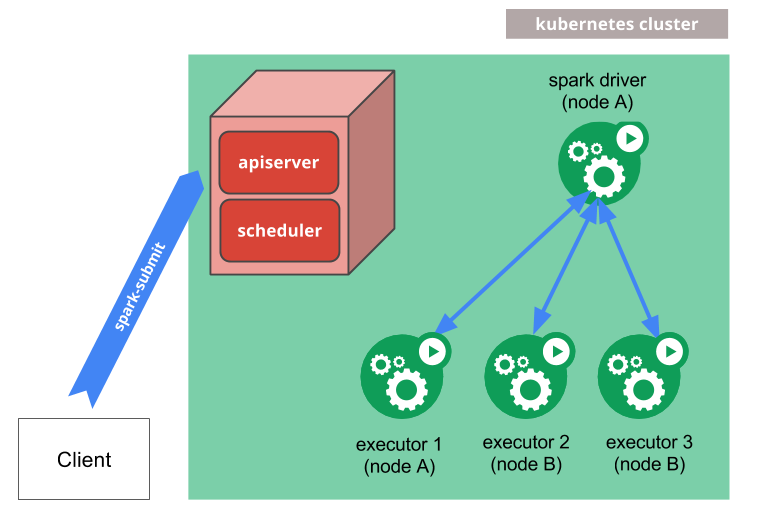
- Spark在Kubernetes pod中创建并运行驱动程序
- 驱动程序在Pod中创建执行器并运行用户代码
- 执行完毕,结束并清理执行器Pod。启动Pod持久化日志并保持k8s的完成状态,等待垃圾回收或者手动清理。注意:在完成状态中并不占用计算或内存资源。
- 驱动和执行Pod由k8s调度,通过fabric8实现。节点选择详见node selector,更多未来功能详见node/pod affinities。
6 应用提交
(1) Docker镜像
K8s需要提供Pod内可部署的镜像,常用Docker镜像。
Sparkx从版本2.3开始提供Dockerfile,详见kubernetes/dockerfiles/。
可以使用bin/docker-image-tool.sh脚本构建并发布支持k8s的镜像。
示例:
1 | 使用默认配置构建并发布,更多详见-h |
(2) 集群模式
1 | ./bin/spark-submit \ |
注意:
master格式配置如上,没有指定http协议时默认使用https。
应用名称使用数字或自渡开头和结束,可包含’_’和’.’。
local指定的资源需要包含在镜像内
1 | kubectl cluster-info |
用于发现可用的API Server
1 | kubectl proxy |
用于设置代理
(3) 客户端模式
版本>=2.4,可以在宿主或Pod中运行客户端模式。
使用客户端模式时,需要考虑一下因素:
1) 网络
执行器可以使用唯一的主机和端口组合访问驱动程序。如果在Pod中启动,可以通过headless service实现,使用spark.driver.host和spark.driver.port配置。
2) 执行器垃圾回收
在Pod中运行驱动时,建议设置spark.kubernetes.driver.pod.name。用于使用OwnerReference关联驱动和执行器,确保删除驱动的同时删除对应的执行器。驱动会在设置的命名空间spark.kubernetes.namespace中查询关联关系。
不在Pod中运行或没有设置pod名称时,可能因为对API Server请求失败等原因导致执行器不能正常回收,需要确保执行器与驱动断连后不会消耗计算资源。可以通过spark.kubernetes.executor.podNamePrefix完全控制执行器名称,建议确保执行器名称全局唯一。
3) 认证参数
使用spark.kubernetes.authenticate作为客户端模式的认证参数。
(4) 依赖管理
使用HDFS或HTTP文件路径
在构建的镜像中,可以在镜像中使用local://或SPARK_EXTRA_CLASSPATH指定。
在作业提交的系统中,可以使用本地文件系统路径。
注意:文件将被上传到同一目录,需要保证文件名唯一。
支持spark.jars, spark.files和spark.archives
(5) 安全管理
使用Secrets实现对安全服务的用户控制。
1 | 对于驱动和执行器的安全管理是在同一命名空间下,形如: |
(6) Pod模版
允许使用template files定义pod。
使用spark.kubernetes.driver.podTemplateFile和spark.kubernetes.executor.podTemplateFile分别设置。文件需要能被spark-submit进程访问。
为了允许驱动Pod访问执行器 Pod, 文件将以Volumes自动挂载到驱动Pod上。
文件验证完全依靠k8s,Spark不做验证。
注意Spark的模某些配置将覆盖k8s的配置,详见full list。
模版可以定义多个容器。使用spark.kubernetes.driver.podTemplateContainerName和spark.kubernetes.executor.podTemplateContainerName指定生效的配置。在没有指定生效配置或制定无效时,默认采用列表第一个配置。
(7) Volumes
1) 支持类型
- hostPath: mounts a file or directory from the host node’s filesystem into a pod.
- emptyDir: an initially empty volume created when a pod is assigned to a node.
- nfs: mounts an existing NFS(Network File System) into a pod.
- persistentVolumeClaim: mounts a
PersistentVolumeinto a pod.
注意:安全详见Security。
2) 使用方式
1 | 配置规则 |
特定类型配置详见Spark Properties。
动态分配示例:
挂载一个名为OnDemand,配置了storageClass和sizeLimit选项的,为每个执行器动态创建persistent volume claim。用于Dynamic Allocation。
1 | spark.kubernetes.executor.volumes.persistentVolumeClaim.data.options.claimName=OnDemand |
(8) 本地存储
Spark支持使用本地存储保存溢出的数据。名称需要以spark-local-dir-开头。
1 | 示例 |
如果没有设置本地存储,Spark将使用scratch space溢出数据。
使用k8s时,会为spark.local.dir或SPARK_LOCAL_DIRS创建emptyDir。缺省使用默认目录。
emptyDir使用k8s的临时存储特性,生命周期在Pod生命周期内。
1) RAM缓存
本地空间较少时,可以使用内存缓存。
spark.kubernetes.local.dirs.tmpfs=true将emptyDir定义为RAM存储的tmpfs。同时需要调整内存申请量spark.kubernetes.memoryOverheadFactor
(9) 监控与调试
1) 日志访问
可以使用k8s API和kubectl。
1 | kubectl -n=<namespace> logs -f <driver-pod-name> |
2) 驱动UI
使用kubectl port-forward映射到宿主机
1 | kubectl port-forward <driver-pod-name> 4040:4040 |
3) 调试
1 | 调度及驱动信息 |
(10) k8s特性
1) 配置文件
用于最初自动配置k8s客户端,保存在.kube/config或KUBECONFIG
2) 上下文
配置文件中可能包含多重配置,用于切换集群和用户。
使用kubectl config current-context查看当前配置
使用spark.kubernetes.context=minikube指定配置
3) 命名空间
命名空间用于在多个用户间区分集群资源,使用spark.kubernetes.namespace指定。
使用ResourceQuota限制资源使用量
4) RBAC
开启RBAC后,用户可以配置Spark访问API Server的角色和服务账户。
最保守情况下,Spark驱动被授予Role or ClusterRole 来创建Pod和服务。默认分配名为default的服务账户。
1 | 创建服务账户spark |
注意:Role只能授予命名空间内的权限,而ClusterRole可以授予集群范围内的权限。
详见:Using RBAC Authorization和Configure Service Accounts for Pods.
(11) Spark应用管理
可以使用namespace:driver-pod-name,缺省使用当前命名空间
1 | 杀掉作业 |
注意:可以使用spark.kubernetes.appKillPodDeletionGracePeriod设置杀死延迟,默认30s。
(12) 未来展望
- Dynamic Resource Allocation and External Shuffle Service
- Job Queues and Resource Management
7 配置
(1) Spark属性
| Property Name | Default | Meaning | Since Version |
|---|---|---|---|
spark.kubernetes.context |
(none) |
The context from the user Kubernetes configuration file used for the initial auto-configuration of the Kubernetes client library. When not specified then the users current context is used. NB: Many of the auto-configured settings can be overridden by the use of other Spark configuration properties e.g. spark.kubernetes.namespace. |
3.0.0 |
spark.kubernetes.driver.master |
https://kubernetes.default.svc |
The internal Kubernetes master (API server) address to be used for driver to request executors. | 3.0.0 |
spark.kubernetes.namespace |
default |
The namespace that will be used for running the driver and executor pods. | 2.3.0 |
spark.kubernetes.container.image |
(none) |
Container image to use for the Spark application. This is usually of the form example.com/repo/spark:v1.0.0. This configuration is required and must be provided by the user, unless explicit images are provided for each different container type. |
2.3.0 |
spark.kubernetes.driver.container.image |
(value of spark.kubernetes.container.image) |
Custom container image to use for the driver. | 2.3.0 |
spark.kubernetes.executor.container.image |
(value of spark.kubernetes.container.image) |
Custom container image to use for executors. | 2.3.0 |
spark.kubernetes.container.image.pullPolicy |
IfNotPresent |
Container image pull policy used when pulling images within Kubernetes. | 2.3.0 |
spark.kubernetes.container.image.pullSecrets |
`` | Comma separated list of Kubernetes secrets used to pull images from private image registries. | 2.4.0 |
spark.kubernetes.allocation.batch.size |
5 |
Number of pods to launch at once in each round of executor pod allocation. | 2.3.0 |
spark.kubernetes.allocation.batch.delay |
1s |
Time to wait between each round of executor pod allocation. Specifying values less than 1 second may lead to excessive CPU usage on the spark driver. | 2.3.0 |
spark.kubernetes.authenticate.submission.caCertFile |
(none) | Path to the CA cert file for connecting to the Kubernetes API server over TLS when starting the driver. This file must be located on the submitting machine’s disk. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.caCertFile instead. |
2.3.0 |
spark.kubernetes.authenticate.submission.clientKeyFile |
(none) | Path to the client key file for authenticating against the Kubernetes API server when starting the driver. This file must be located on the submitting machine’s disk. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.clientKeyFile instead. |
2.3.0 |
spark.kubernetes.authenticate.submission.clientCertFile |
(none) | Path to the client cert file for authenticating against the Kubernetes API server when starting the driver. This file must be located on the submitting machine’s disk. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.clientCertFile instead. |
2.3.0 |
spark.kubernetes.authenticate.submission.oauthToken |
(none) | OAuth token to use when authenticating against the Kubernetes API server when starting the driver. Note that unlike the other authentication options, this is expected to be the exact string value of the token to use for the authentication. In client mode, use spark.kubernetes.authenticate.oauthToken instead. |
2.3.0 |
spark.kubernetes.authenticate.submission.oauthTokenFile |
(none) | Path to the OAuth token file containing the token to use when authenticating against the Kubernetes API server when starting the driver. This file must be located on the submitting machine’s disk. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.oauthTokenFile instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.caCertFile |
(none) | Path to the CA cert file for connecting to the Kubernetes API server over TLS from the driver pod when requesting executors. This file must be located on the submitting machine’s disk, and will be uploaded to the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.caCertFile instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.clientKeyFile |
(none) | Path to the client key file for authenticating against the Kubernetes API server from the driver pod when requesting executors. This file must be located on the submitting machine’s disk, and will be uploaded to the driver pod as a Kubernetes secret. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.clientKeyFile instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.clientCertFile |
(none) | Path to the client cert file for authenticating against the Kubernetes API server from the driver pod when requesting executors. This file must be located on the submitting machine’s disk, and will be uploaded to the driver pod as a Kubernetes secret. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.clientCertFile instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.oauthToken |
(none) | OAuth token to use when authenticating against the Kubernetes API server from the driver pod when requesting executors. Note that unlike the other authentication options, this must be the exact string value of the token to use for the authentication. This token value is uploaded to the driver pod as a Kubernetes secret. In client mode, use spark.kubernetes.authenticate.oauthToken instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.oauthTokenFile |
(none) | Path to the OAuth token file containing the token to use when authenticating against the Kubernetes API server from the driver pod when requesting executors. Note that unlike the other authentication options, this file must contain the exact string value of the token to use for the authentication. This token value is uploaded to the driver pod as a secret. In client mode, use spark.kubernetes.authenticate.oauthTokenFile instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.mounted.caCertFile |
(none) | Path to the CA cert file for connecting to the Kubernetes API server over TLS from the driver pod when requesting executors. This path must be accessible from the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.caCertFile instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.mounted.clientKeyFile |
(none) | Path to the client key file for authenticating against the Kubernetes API server from the driver pod when requesting executors. This path must be accessible from the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.clientKeyFile instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.mounted.clientCertFile |
(none) | Path to the client cert file for authenticating against the Kubernetes API server from the driver pod when requesting executors. This path must be accessible from the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). In client mode, use spark.kubernetes.authenticate.clientCertFile instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.mounted.oauthTokenFile |
(none) | Path to the file containing the OAuth token to use when authenticating against the Kubernetes API server from the driver pod when requesting executors. This path must be accessible from the driver pod. Note that unlike the other authentication options, this file must contain the exact string value of the token to use for the authentication. In client mode, use spark.kubernetes.authenticate.oauthTokenFile instead. |
2.3.0 |
spark.kubernetes.authenticate.driver.serviceAccountName |
default |
Service account that is used when running the driver pod. The driver pod uses this service account when requesting executor pods from the API server. Note that this cannot be specified alongside a CA cert file, client key file, client cert file, and/or OAuth token. In client mode, use spark.kubernetes.authenticate.serviceAccountName instead. |
2.3.0 |
spark.kubernetes.authenticate.caCertFile |
(none) | In client mode, path to the CA cert file for connecting to the Kubernetes API server over TLS when requesting executors. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). | 2.4.0 |
spark.kubernetes.authenticate.clientKeyFile |
(none) | In client mode, path to the client key file for authenticating against the Kubernetes API server when requesting executors. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). | 2.4.0 |
spark.kubernetes.authenticate.clientCertFile |
(none) | In client mode, path to the client cert file for authenticating against the Kubernetes API server when requesting executors. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). | 2.4.0 |
spark.kubernetes.authenticate.oauthToken |
(none) | In client mode, the OAuth token to use when authenticating against the Kubernetes API server when requesting executors. Note that unlike the other authentication options, this must be the exact string value of the token to use for the authentication. | 2.4.0 |
spark.kubernetes.authenticate.oauthTokenFile |
(none) | In client mode, path to the file containing the OAuth token to use when authenticating against the Kubernetes API server when requesting executors. | 2.4.0 |
spark.kubernetes.driver.label.[LabelName] |
(none) | Add the label specified by LabelName to the driver pod. For example, spark.kubernetes.driver.label.something=true. Note that Spark also adds its own labels to the driver pod for bookkeeping purposes. |
2.3.0 |
spark.kubernetes.driver.annotation.[AnnotationName] |
(none) | Add the Kubernetes annotation specified by AnnotationName to the driver pod. For example, spark.kubernetes.driver.annotation.something=true. |
2.3.0 |
spark.kubernetes.driver.service.annotation.[AnnotationName] |
(none) | Add the Kubernetes annotation specified by AnnotationName to the driver service. For example, spark.kubernetes.driver.service.annotation.something=true. |
3.0.0 |
spark.kubernetes.executor.label.[LabelName] |
(none) | Add the label specified by LabelName to the executor pods. For example, spark.kubernetes.executor.label.something=true. Note that Spark also adds its own labels to the executor pod for bookkeeping purposes. |
2.3.0 |
spark.kubernetes.executor.annotation.[AnnotationName] |
(none) | Add the Kubernetes annotation specified by AnnotationName to the executor pods. For example, spark.kubernetes.executor.annotation.something=true. |
2.3.0 |
spark.kubernetes.driver.pod.name |
(none) | Name of the driver pod. In cluster mode, if this is not set, the driver pod name is set to “spark.app.name” suffixed by the current timestamp to avoid name conflicts. In client mode, if your application is running inside a pod, it is highly recommended to set this to the name of the pod your driver is running in. Setting this value in client mode allows the driver to become the owner of its executor pods, which in turn allows the executor pods to be garbage collected by the cluster. | 2.3.0 |
spark.kubernetes.executor.podNamePrefix |
(none) | Prefix to use in front of the executor pod names. | 2.3.0 |
spark.kubernetes.executor.lostCheck.maxAttempts |
10 |
Number of times that the driver will try to ascertain the loss reason for a specific executor. The loss reason is used to ascertain whether the executor failure is due to a framework or an application error which in turn decides whether the executor is removed and replaced, or placed into a failed state for debugging. | 2.3.0 |
spark.kubernetes.submission.waitAppCompletion |
true |
In cluster mode, whether to wait for the application to finish before exiting the launcher process. When changed to false, the launcher has a “fire-and-forget” behavior when launching the Spark job. | 2.3.0 |
spark.kubernetes.report.interval |
1s |
Interval between reports of the current Spark job status in cluster mode. | 2.3.0 |
spark.kubernetes.driver.request.cores |
(none) | Specify the cpu request for the driver pod. Values conform to the Kubernetes convention. Example values include 0.1, 500m, 1.5, 5, etc., with the definition of cpu units documented in CPU units. This takes precedence over spark.driver.cores for specifying the driver pod cpu request if set. |
3.0.0 |
spark.kubernetes.driver.limit.cores |
(none) | Specify a hard cpu limit for the driver pod. | 2.3.0 |
spark.kubernetes.executor.request.cores |
(none) | Specify the cpu request for each executor pod. Values conform to the Kubernetes convention. Example values include 0.1, 500m, 1.5, 5, etc., with the definition of cpu units documented in CPU units. This is distinct from spark.executor.cores: it is only used and takes precedence over spark.executor.cores for specifying the executor pod cpu request if set. Task parallelism, e.g., number of tasks an executor can run concurrently is not affected by this. |
2.4.0 |
spark.kubernetes.executor.limit.cores |
(none) | Specify a hard cpu limit for each executor pod launched for the Spark Application. | 2.3.0 |
spark.kubernetes.node.selector.[labelKey] |
(none) | Adds to the node selector of the driver pod and executor pods, with key labelKey and the value as the configuration’s value. For example, setting spark.kubernetes.node.selector.identifier to myIdentifier will result in the driver pod and executors having a node selector with key identifier and value myIdentifier. Multiple node selector keys can be added by setting multiple configurations with this prefix. |
2.3.0 |
spark.kubernetes.driverEnv.[EnvironmentVariableName] |
(none) | Add the environment variable specified by EnvironmentVariableName to the Driver process. The user can specify multiple of these to set multiple environment variables. |
2.3.0 |
spark.kubernetes.driver.secrets.[SecretName] |
(none) | Add the Kubernetes Secret named SecretName to the driver pod on the path specified in the value. For example, spark.kubernetes.driver.secrets.spark-secret=/etc/secrets. |
2.3.0 |
spark.kubernetes.executor.secrets.[SecretName] |
(none) | Add the Kubernetes Secret named SecretName to the executor pod on the path specified in the value. For example, spark.kubernetes.executor.secrets.spark-secret=/etc/secrets. |
2.3.0 |
spark.kubernetes.driver.secretKeyRef.[EnvName] |
(none) | Add as an environment variable to the driver container with name EnvName (case sensitive), the value referenced by key keyin the data of the referenced Kubernetes Secret. For example, spark.kubernetes.driver.secretKeyRef.ENV_VAR=spark-secret:key. |
2.4.0 |
spark.kubernetes.executor.secretKeyRef.[EnvName] |
(none) | Add as an environment variable to the executor container with name EnvName (case sensitive), the value referenced by key keyin the data of the referenced Kubernetes Secret. For example, spark.kubernetes.executor.secrets.ENV_VAR=spark-secret:key. |
2.4.0 |
spark.kubernetes.driver.volumes.[VolumeType].[VolumeName].mount.path |
(none) | Add the Kubernetes Volume named VolumeName of the VolumeType type to the driver pod on the path specified in the value. For example, spark.kubernetes.driver.volumes.persistentVolumeClaim.checkpointpvc.mount.path=/checkpoint. |
2.4.0 |
spark.kubernetes.driver.volumes.[VolumeType].[VolumeName].mount.subPath |
(none) | Specifies a subpath to be mounted from the volume into the driver pod. spark.kubernetes.driver.volumes.persistentVolumeClaim.checkpointpvc.mount.subPath=checkpoint. |
3.0.0 |
spark.kubernetes.driver.volumes.[VolumeType].[VolumeName].mount.readOnly |
(none) | Specify if the mounted volume is read only or not. For example, spark.kubernetes.driver.volumes.persistentVolumeClaim.checkpointpvc.mount.readOnly=false. |
2.4.0 |
spark.kubernetes.driver.volumes.[VolumeType].[VolumeName].options.[OptionName] |
(none) | Configure Kubernetes Volume options passed to the Kubernetes with OptionName as key having specified value, must conform with Kubernetes option format. For example, spark.kubernetes.driver.volumes.persistentVolumeClaim.checkpointpvc.options.claimName=spark-pvc-claim. |
2.4.0 |
spark.kubernetes.executor.volumes.[VolumeType].[VolumeName].mount.path |
(none) | Add the Kubernetes Volume named VolumeName of the VolumeType type to the executor pod on the path specified in the value. For example, spark.kubernetes.executor.volumes.persistentVolumeClaim.checkpointpvc.mount.path=/checkpoint. |
2.4.0 |
spark.kubernetes.executor.volumes.[VolumeType].[VolumeName].mount.subPath |
(none) | Specifies a subpath to be mounted from the volume into the executor pod. spark.kubernetes.executor.volumes.persistentVolumeClaim.checkpointpvc.mount.subPath=checkpoint. |
3.0.0 |
spark.kubernetes.executor.volumes.[VolumeType].[VolumeName].mount.readOnly |
false | Specify if the mounted volume is read only or not. For example, spark.kubernetes.executor.volumes.persistentVolumeClaim.checkpointpvc.mount.readOnly=false. |
2.4.0 |
spark.kubernetes.executor.volumes.[VolumeType].[VolumeName].options.[OptionName] |
(none) | Configure Kubernetes Volume options passed to the Kubernetes with OptionName as key having specified value. For example, spark.kubernetes.executor.volumes.persistentVolumeClaim.checkpointpvc.options.claimName=spark-pvc-claim. |
2.4.0 |
spark.kubernetes.local.dirs.tmpfs |
false |
Configure the emptyDir volumes used to back SPARK_LOCAL_DIRS within the Spark driver and executor pods to use tmpfs backing i.e. RAM. See Local Storage earlier on this page for more discussion of this. |
3.0.0 |
spark.kubernetes.memoryOverheadFactor |
0.1 |
This sets the Memory Overhead Factor that will allocate memory to non-JVM memory, which includes off-heap memory allocations, non-JVM tasks, and various systems processes. For JVM-based jobs this value will default to 0.10 and 0.40 for non-JVM jobs. This is done as non-JVM tasks need more non-JVM heap space and such tasks commonly fail with “Memory Overhead Exceeded” errors. This preempts this error with a higher default. | 2.4.0 |
spark.kubernetes.pyspark.pythonVersion |
"3" |
This sets the major Python version of the docker image used to run the driver and executor containers. It can be only “3”. This configuration was deprecated from Spark 3.1.0, and is effectively no-op. Users should set ‘spark.pyspark.python’ and ‘spark.pyspark.driver.python’ configurations or ‘PYSPARK_PYTHON’ and ‘PYSPARK_DRIVER_PYTHON’ environment variables. | 2.4.0 |
spark.kubernetes.kerberos.krb5.path |
(none) |
Specify the local location of the krb5.conf file to be mounted on the driver and executors for Kerberos interaction. It is important to note that the KDC defined needs to be visible from inside the containers. | 3.0.0 |
spark.kubernetes.kerberos.krb5.configMapName |
(none) |
Specify the name of the ConfigMap, containing the krb5.conf file, to be mounted on the driver and executors for Kerberos interaction. The KDC defined needs to be visible from inside the containers. The ConfigMap must also be in the same namespace of the driver and executor pods. | 3.0.0 |
spark.kubernetes.hadoop.configMapName |
(none) |
Specify the name of the ConfigMap, containing the HADOOP_CONF_DIR files, to be mounted on the driver and executors for custom Hadoop configuration. | 3.0.0 |
spark.kubernetes.kerberos.tokenSecret.name |
(none) |
Specify the name of the secret where your existing delegation tokens are stored. This removes the need for the job user to provide any kerberos credentials for launching a job. | 3.0.0 |
spark.kubernetes.kerberos.tokenSecret.itemKey |
(none) |
Specify the item key of the data where your existing delegation tokens are stored. This removes the need for the job user to provide any kerberos credentials for launching a job. | 3.0.0 |
spark.kubernetes.driver.podTemplateFile |
(none) | Specify the local file that contains the driver pod template. For example spark.kubernetes.driver.podTemplateFile=/path/to/driver-pod-template.yaml |
3.0.0 |
spark.kubernetes.driver.podTemplateContainerName |
(none) | Specify the container name to be used as a basis for the driver in the given pod template. For example spark.kubernetes.driver.podTemplateContainerName=spark-driver |
3.0.0 |
spark.kubernetes.executor.podTemplateFile |
(none) | Specify the local file that contains the executor pod template. For example spark.kubernetes.executor.podTemplateFile=/path/to/executor-pod-template.yaml |
3.0.0 |
spark.kubernetes.executor.podTemplateContainerName |
(none) | Specify the container name to be used as a basis for the executor in the given pod template. For example spark.kubernetes.executor.podTemplateContainerName=spark-executor |
3.0.0 |
spark.kubernetes.executor.deleteOnTermination |
true | Specify whether executor pods should be deleted in case of failure or normal termination. | 3.0.0 |
spark.kubernetes.executor.checkAllContainers |
false | Specify whether executor pods should be check all containers (including sidecars) or only the executor container when determining the pod status. | 3.1.0 |
spark.kubernetes.submission.connectionTimeout |
10000 | Connection timeout in milliseconds for the kubernetes client to use for starting the driver. | 3.0.0 |
spark.kubernetes.submission.requestTimeout |
10000 | Request timeout in milliseconds for the kubernetes client to use for starting the driver. | 3.0.0 |
spark.kubernetes.driver.connectionTimeout |
10000 | Connection timeout in milliseconds for the kubernetes client in driver to use when requesting executors. | 3.0.0 |
spark.kubernetes.driver.requestTimeout |
10000 | Request timeout in milliseconds for the kubernetes client in driver to use when requesting executors. | 3.0.0 |
spark.kubernetes.appKillPodDeletionGracePeriod |
(none) | Specify the grace period in seconds when deleting a Spark application using spark-submit. | 3.0.0 |
spark.kubernetes.file.upload.path |
(none) | Path to store files at the spark submit side in cluster mode. For example: spark.kubernetes.file.upload.path=s3a://<s3-bucket>/path File should specified as file://path/to/fileor absolute path. |
3.0.0 |
(3) Pod元数据
| Pod metadata key | Modified value | Description |
|---|---|---|
| name | Value of spark.kubernetes.driver.pod.name |
The driver pod name will be overwritten with either the configured or default value of spark.kubernetes.driver.pod.name. The executor pod names will be unaffected. |
| namespace | Value of spark.kubernetes.namespace |
Spark makes strong assumptions about the driver and executor namespaces. Both driver and executor namespaces will be replaced by either the configured or default spark conf value. |
| labels | Adds the labels from spark.kubernetes.{driver,executor}.label.* |
Spark will add additional labels specified by the spark configuration. |
| annotations | Adds the annotations from spark.kubernetes.{driver,executor}.annotation.* |
Spark will add additional annotations specified by the spark configuration. |
(4) Pod规范
| Pod spec key | Modified value | Description |
|---|---|---|
| imagePullSecrets | Adds image pull secrets from spark.kubernetes.container.image.pullSecrets |
Additional pull secrets will be added from the spark configuration to both executor pods. |
| nodeSelector | Adds node selectors from spark.kubernetes.node.selector.* |
Additional node selectors will be added from the spark configuration to both executor pods. |
| restartPolicy | "never" |
Spark assumes that both drivers and executors never restart. |
| serviceAccount | Value of spark.kubernetes.authenticate.driver.serviceAccountName |
Spark will override serviceAccount with the value of the spark configuration for only driver pods, and only if the spark configuration is specified. Executor pods will remain unaffected. |
| serviceAccountName | Value of spark.kubernetes.authenticate.driver.serviceAccountName |
Spark will override serviceAccountName with the value of the spark configuration for only driver pods, and only if the spark configuration is specified. Executor pods will remain unaffected. |
| volumes | Adds volumes from spark.kubernetes.{driver,executor}.volumes.[VolumeType].[VolumeName].mount.path |
Spark will add volumes as specified by the spark conf, as well as additional volumes necessary for passing spark conf and pod template files. |
(5) 容器规范
| Container spec key | Modified value | Description |
|---|---|---|
| env | Adds env variables from spark.kubernetes.driverEnv.[EnvironmentVariableName] |
Spark will add driver env variables from spark.kubernetes.driverEnv.[EnvironmentVariableName], and executor env variables from spark.executorEnv.[EnvironmentVariableName]. |
| image | Value of spark.kubernetes.{driver,executor}.container.image |
The image will be defined by the spark configurations. |
| imagePullPolicy | Value of spark.kubernetes.container.image.pullPolicy |
Spark will override the pull policy for both driver and executors. |
| name | See description | The container name will be assigned by spark (“spark-kubernetes-driver” for the driver container, and “spark-kubernetes-executor” for each executor container) if not defined by the pod template. If the container is defined by the template, the template’s name will be used. |
| resources | See description | The cpu limits are set by spark.kubernetes.{driver,executor}.limit.cores. The cpu is set by spark.{driver,executor}.cores. The memory request and limit are set by summing the values of spark.{driver,executor}.memory and spark.{driver,executor}.memoryOverhead. Other resource limits are set by spark.{driver,executor}.resources.{resourceName}.* configs. |
| volumeMounts | Add volumes from spark.kubernetes.driver.volumes.[VolumeType].[VolumeName].mount.{path,readOnly} |
Spark will add volumes as specified by the spark conf, as well as additional volumes necessary for passing spark conf and pod template files. |
(6) 资源分配
自定义资源调度和配置详见 configuration page。
资源配置应保证容器间资源隔离,或者使用资源发现脚本保证,详见custom resources。
Spark支持自动转换spark.{driver/executor}.resource.{resourceType}到k8s配置,前提是使用spark.{driver/executor}.resource.{resourceType}.vendor设置和按照k8s 设备插件格式命名vendor-domain/resourcetype。Spark只支持设置资源的上限。
k8s不会告知Spark分配给每个容器的资源地址,需要定义发现脚本。示例详见examples/src/main/scripts/getGpusResources.sh。需要保证具有执行权限,并避免被恶意修改。
(7) 阶段级别调度
当开启动态资源分配事,k8s支持阶段级别调度。因为k8s当前不支持外部shuffle服务,需要开启spark.dynamicAllocation.shuffleTracking.enabled。k8s不保证获取在不同容器配置文件中获取的顺序。
注意:由于k8s动态分配需要shuffle跟踪特性,之前阶段使用的、具有不同资源配置的且存有shuffle数据的执行器可能不会因为空闲而超时。可能最终导致因没有可用资源而挂起。可以使用spark.dynamicAllocation.shuffleTracking.timeout配置超时,但是可能导致需要的shuffle数据被再次计算。
注意:Pod模版的基本默认配置和自定义配置的处理方式不同。Pod模版中配置的资源只会在基本默认配置中使用,自定义配置需要保证包含了其中必要的配置。